Debugging SIMD registers in VS Code
Contrary to some opinions, it can be quite useful to have some visibility into what your code is doing1. Unfortunately, if you are writing x86 SIMD code (SSE or AVX), the support provided by gdb and lldb is not so great.
For starters, each SIMD register can be divided into multiple lanes. For example, a 128-bit wide register can be divided the following way:
- 64x2 – two lanes of 64-bit integers,
- 32x4 – four lanes of 32-bit integers,
- 16x8 – eight lanes of 16-bit integers,
- 8x16 – sixteen lanes of 8-bit integers.
The register doesn’t care what’s inside, it just holds 128 bits of data. The instructions that operate on the register, however, do care. It matters a lot if you want to add four 32-bit integers, or if you want to add sixteen 8-bit integers.
ARM NEON Link to heading
The ARM implementation of SIMD, called NEON, got it right when it comes to data types. Each of the possible lane splits has its own type, and the debugger knows how to print it. For example, the following variables:
uint8x16_t cg = vsubq_u8( lg, vdupq_n_u8( rming ) );
uint16x8_t is0l = vaddl_u8( vget_low_u8( cr ), vget_low_u8( cg ) );
Are printed out, as we would expect, as either 16 or 8 values, even though the underlying register is the same width in both cases:
(lldb) p cg
(uint8x16_t) (0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00)
(lldb) p is0l
(uint16x8_t) (1, 0, 0, 0, 0, 0, 0, 0)
One downside to this is that we may need to cast one type to the other on occasion, and in some cases this can be quite intensive. For example, we may want to compute the per-channel (8-bit) maximum of each color with the vmaxq_u8 intrinsic, but then we may want to shuffle the order of the 32-bit colors with vrev64q_u322. This requires casting from 8x16 to 32x4 and then back to 8x16:
uint8x16_t max2 = vmaxq_u8( max0, max1 );
uint8x16_t max3 = vreinterpretq_u8_u32( vrev64q_u32( vreinterpretq_u32_u8( max2 ) ) );
SSE, AVX Link to heading
On x86 there is just one data type for each of the register widths: __m128i, __m256i, __m512i3. This is a problem because the debugger can only print the register as a representation of the implementation detail4, not as the lanes we are interested in.
So, this variable:
__m128i vPxa = _mm_loadu_si128( (const __m128i *)pPixels );
Is printed by gdb as:
(gdb) p vPxa
$1 = {8341503235886217471, 8629733612088195327}
And by lldb as:
(lldb) v vPxa
(__m128i) vPxa = (8341503235886217471, 8629733612088195327)
Note that the only thing we can infer from the instruction itself, _mm_loadu_si128, is that we are loading 128 bits of data. But if we look at the variable name, pPixels, we see that these 128 bits should probably be displayed as either four uint32 values representing pixels, or sixteen uint8 values representing the four RGBA color channels of each of the four pixels.
Pretty printers Link to heading
Debuggers support pretty-printing of data structures. You are already using pretty-printing, even if you don’t realize it. For example, suppose you have the following variable:
std::vector<std::string> v = { "Później", "mówiono", "że", "człowiek", "ten", "nadszedł", "od", "północy" };
The debugger will print it out as:
(lldb) v v
(std::vector<std::basic_string<char> >) v = size=8 {
[0] = "Później"
[1] = "mówiono"
[2] = "że"
[3] = "człowiek"
[4] = "ten"
[5] = "nadszedł"
[6] = "od"
[7] = "północy"
}
There are two pretty printers at work here. The first one for std::vector, enumerating all the vector elements. The second one for std::string, printing out the actual strings, instead of some internal data pointers like in the example below:
(gdb) print s
$1 = {
static npos = 4294967295,
_M_dataplus = {
<std::allocator<char>> = {
<__gnu_cxx::new_allocator<char>> = {
<No data fields>}, <No data fields>
},
members of std::basic_string<char, std::char_traits<char>,
std::allocator<char> >::_Alloc_hider:
_M_p = 0x804a014 "abcd"
}
}
Pretty printing SIMD registers Link to heading
Because of my setup, I am interested in making things work in lldb. Pretty printing in lldb is done with Python scripts. You can read some quite dense documentation on the topic, and there are a grant total of two posts on the internet that try to present things in a more manageable way.
Without further ado, here’s the script for printing SIMD registers. Writing it wasn’t easy.
# SSE/AVX pretty printer for LLDB
# Author: Bartosz Taudul <wolf@nereid.pl>
# Made available under the BSD 3-clause license
import lldb
class Simd128Printer:
def __init__(self, valobj, internal_dict):
self.valobj = valobj
def update(self):
self.v0 = self.valobj.GetChildAtIndex(0).GetValueAsUnsigned()
self.v1 = self.valobj.GetChildAtIndex(1).GetValueAsUnsigned()
def num_children(self):
return 8
def get_child_index(self, name):
return int(name.lstrip('[').rstrip(']'))
def get_child_at_index(self, index):
if index == 0:
return self.valobj.CreateValueFromExpression('u8x16', 'uint16_t ppx[16] = {' + str(self.v0 & 0xFF) + ',' + str((self.v0 >> 8) & 0xFF) + ',' + str((self.v0 >> 16) & 0xFF) + ',' + str((self.v0 >> 24) & 0xFF) + ',' + str((self.v0 >> 32) & 0xFF) + ',' + str((self.v0 >> 40) & 0xFF) + ',' + str((self.v0 >> 48) & 0xFF) + ',' + str(self.v0 >> 56) + ',' + str(self.v1 & 0xFF) + ',' + str((self.v1 >> 8) & 0xFF) + ',' + str((self.v1 >> 16) & 0xFF) + ',' + str((self.v1 >> 24) & 0xFF) + ',' + str((self.v1 >> 32) & 0xFF) + ',' + str((self.v1 >> 40) & 0xFF) + ',' + str((self.v1 >> 48) & 0xFF) + ',' + str(self.v1 >> 56) + '}; ppx')
elif index == 1:
return self.valobj.CreateValueFromExpression('i8x16', 'int16_t ppx[16] = {(int8_t)' + str(self.v0 & 0xFF) + ',(int8_t)' + str((self.v0 >> 8) & 0xFF) + ',(int8_t)' + str((self.v0 >> 16) & 0xFF) + ',(int8_t)' + str((self.v0 >> 24) & 0xFF) + ',(int8_t)' + str((self.v0 >> 32) & 0xFF) + ',(int8_t)' + str((self.v0 >> 40) & 0xFF) + ',(int8_t)' + str((self.v0 >> 48) & 0xFF) + ',(int8_t)' + str(self.v0 >> 56) + ',(int8_t)' + str(self.v1 & 0xFF) + ',(int8_t)' + str((self.v1 >> 8) & 0xFF) + ',(int8_t)' + str((self.v1 >> 16) & 0xFF) + ',(int8_t)' + str((self.v1 >> 24) & 0xFF) + ',(int8_t)' + str((self.v1 >> 32) & 0xFF) + ',(int8_t)' + str((self.v1 >> 40) & 0xFF) + ',(int8_t)' + str((self.v1 >> 48) & 0xFF) + ',(int8_t)' + str(self.v1 >> 56) + '}; ppx')
elif index == 2:
return self.valobj.CreateValueFromExpression('u16x8', 'uint16_t ppx[8] = {' + str(self.v0 & 0xFFFF) + ',' + str((self.v0 >> 16) & 0xFFFF) + ',' + str((self.v0 >> 32) & 0xFFFF) + ',' + str(self.v0 >> 48) + ',' + str(self.v1 & 0xFFFF) + ',' + str((self.v1 >> 16) & 0xFFFF) + ',' + str((self.v1 >> 32) & 0xFFFF) + ',' + str(self.v1 >> 48) + '}; ppx')
elif index == 3:
return self.valobj.CreateValueFromExpression('i16x8', 'int16_t ppx[8] = {(int16_t)' + str(self.v0 & 0xFFFF) + ',(int16_t)' + str((self.v0 >> 16) & 0xFFFF) + ',(int16_t)' + str((self.v0 >> 32) & 0xFFFF) + ',(int16_t)' + str(self.v0 >> 48) + ',(int16_t)' + str(self.v1 & 0xFFFF) + ',(int16_t)' + str((self.v1 >> 16) & 0xFFFF) + ',(int16_t)' + str((self.v1 >> 32) & 0xFFFF) + ',(int16_t)' + str(self.v1 >> 48) + '}; ppx')
elif index == 4:
return self.valobj.CreateValueFromExpression('u32x4', 'uint32_t ppx[4] = {' + str(self.v0 & 0xFFFFFFFF) + ',' + str(self.v0 >> 32) + ',' + str(self.v1 & 0xFFFFFFFF) + ',' + str(self.v1 >> 32) + '}; ppx')
elif index == 5:
return self.valobj.CreateValueFromExpression('i32x4', 'int32_t ppx[4] = {(int32_t)' + str(self.v0 & 0xFFFFFFFF) + ',(int32_t)' + str(self.v0 >> 32) + ',(int32_t)' + str(self.v1 & 0xFFFFFFFF) + ',(int32_t)' + str(self.v1 >> 32) + '}; ppx')
elif index == 6:
return self.valobj.CreateValueFromExpression('u64x2', 'uint64_t ppx[2] = {' + str(self.v0) + ',' + str(self.v1) + '}; ppx')
elif index == 7:
return self.valobj.CreateValueFromExpression('i64x2', 'int64_t ppx[2] = {(int64_t)' + str(self.v0) + ',(int64_t)' + str(self.v1) + '}; ppx')
else:
return None
class Simd256Printer:
def __init__(self, valobj, internal_dict):
self.valobj = valobj
def update(self):
self.v0 = self.valobj.GetChildAtIndex(0).GetValueAsUnsigned()
self.v1 = self.valobj.GetChildAtIndex(1).GetValueAsUnsigned()
self.v2 = self.valobj.GetChildAtIndex(2).GetValueAsUnsigned()
self.v3 = self.valobj.GetChildAtIndex(3).GetValueAsUnsigned()
def num_children(self):
return 8
def get_child_index(self, name):
return int(name.lstrip('[').rstrip(']'))
def get_child_at_index(self, index):
if index == 0:
return self.valobj.CreateValueFromExpression('u8x32', 'uint16_t ppx[32] = {' + str(self.v0 & 0xFF) + ',' + str((self.v0 >> 8) & 0xFF) + ',' + str((self.v0 >> 16) & 0xFF) + ',' + str((self.v0 >> 24) & 0xFF) + ',' + str((self.v0 >> 32) & 0xFF) + ',' + str((self.v0 >> 40) & 0xFF) + ',' + str((self.v0 >> 48) & 0xFF) + ',' + str(self.v0 >> 56) + ',' + str(self.v1 & 0xFF) + ',' + str((self.v1 >> 8) & 0xFF) + ',' + str((self.v1 >> 16) & 0xFF) + ',' + str((self.v1 >> 24) & 0xFF) + ',' + str((self.v1 >> 32) & 0xFF) + ',' + str((self.v1 >> 40) & 0xFF) + ',' + str((self.v1 >> 48) & 0xFF) + ',' + str(self.v1 >> 56) + ',' + str(self.v2 & 0xFF) + ',' + str((self.v2 >> 8) & 0xFF) + ',' + str((self.v2 >> 16) & 0xFF) + ',' + str((self.v2 >> 24) & 0xFF) + ',' + str((self.v2 >> 32) & 0xFF) + ',' + str((self.v2 >> 40) & 0xFF) + ',' + str((self.v2 >> 48) & 0xFF) + ',' + str(self.v2 >> 56) + ',' + str(self.v3 & 0xFF) + ',' + str((self.v3 >> 8) & 0xFF) + ',' + str((self.v3 >> 16) & 0xFF) + ',' + str((self.v3 >> 24) & 0xFF) + ',' + str((self.v3 >> 32) & 0xFF) + ',' + str((self.v3 >> 40) & 0xFF) + ',' + str((self.v3 >> 48) & 0xFF) + ',' + str(self.v3 >> 56) + '}; ppx')
elif index == 1:
return self.valobj.CreateValueFromExpression('i8x32', 'int16_t ppx[32] = {(int8_t)' + str(self.v0 & 0xFF) + ',(int8_t)' + str((self.v0 >> 8) & 0xFF) + ',(int8_t)' + str((self.v0 >> 16) & 0xFF) + ',(int8_t)' + str((self.v0 >> 24) & 0xFF) + ',(int8_t)' + str((self.v0 >> 32) & 0xFF) + ',(int8_t)' + str((self.v0 >> 40) & 0xFF) + ',(int8_t)' + str((self.v0 >> 48) & 0xFF) + ',(int8_t)' + str(self.v0 >> 56) + ',(int8_t)' + str(self.v1 & 0xFF) + ',(int8_t)' + str((self.v1 >> 8) & 0xFF) + ',(int8_t)' + str((self.v1 >> 16) & 0xFF) + ',(int8_t)' + str((self.v1 >> 24) & 0xFF) + ',(int8_t)' + str((self.v1 >> 32) & 0xFF) + ',(int8_t)' + str((self.v1 >> 40) & 0xFF) + ',(int8_t)' + str((self.v1 >> 48) & 0xFF) + ',(int8_t)' + str(self.v1 >> 56) + ',(int8_t)' + str(self.v2 & 0xFF) + ',(int8_t)' + str((self.v2 >> 8) & 0xFF) + ',(int8_t)' + str((self.v2 >> 16) & 0xFF) + ',(int8_t)' + str((self.v2 >> 24) & 0xFF) + ',(int8_t)' + str((self.v2 >> 32) & 0xFF) + ',(int8_t)' + str((self.v2 >> 40) & 0xFF) + ',(int8_t)' + str((self.v2 >> 48) & 0xFF) + ',(int8_t)' + str(self.v2 >> 56) + ',(int8_t)' + str(self.v3 & 0xFF) + ',(int8_t)' + str((self.v3 >> 8) & 0xFF) + ',(int8_t)' + str((self.v3 >> 16) & 0xFF) + ',(int8_t)' + str((self.v3 >> 24) & 0xFF) + ',(int8_t)' + str((self.v3 >> 32) & 0xFF) + ',(int8_t)' + str((self.v3 >> 40) & 0xFF) + ',(int8_t)' + str((self.v3 >> 48) & 0xFF) + ',(int8_t)' + str(self.v3 >> 56) + '}; ppx')
elif index == 2:
return self.valobj.CreateValueFromExpression('u16x16', 'uint16_t ppx[16] = {' + str(self.v0 & 0xFFFF) + ',' + str((self.v0 >> 16) & 0xFFFF) + ',' + str((self.v0 >> 32) & 0xFFFF) + ',' + str(self.v0 >> 48) + ',' + str(self.v1 & 0xFFFF) + ',' + str((self.v1 >> 16) & 0xFFFF) + ',' + str((self.v1 >> 32) & 0xFFFF) + ',' + str(self.v1 >> 48) + ',' + str(self.v2 & 0xFFFF) + ',' + str((self.v2 >> 16) & 0xFFFF) + ',' + str((self.v2 >> 32) & 0xFFFF) + ',' + str(self.v2 >> 48) + ',' + str(self.v3 & 0xFFFF) + ',' + str((self.v3 >> 16) & 0xFFFF) + ',' + str((self.v3 >> 32) & 0xFFFF) + ',' + str(self.v3 >> 48) + '}; ppx')
elif index == 3:
return self.valobj.CreateValueFromExpression('i16x16', 'int16_t ppx[16] = {(int16_t)' + str(self.v0 & 0xFFFF) + ',(int16_t)' + str((self.v0 >> 16) & 0xFFFF) + ',(int16_t)' + str((self.v0 >> 32) & 0xFFFF) + ',(int16_t)' + str(self.v0 >> 48) + ',(int16_t)' + str(self.v1 & 0xFFFF) + ',(int16_t)' + str((self.v1 >> 16) & 0xFFFF) + ',(int16_t)' + str((self.v1 >> 32) & 0xFFFF) + ',(int16_t)' + str(self.v1 >> 48) + ',(int16_t)' + str(self.v2 & 0xFFFF) + ',(int16_t)' + str((self.v2 >> 16) & 0xFFFF) + ',(int16_t)' + str((self.v2 >> 32) & 0xFFFF) + ',(int16_t)' + str(self.v2 >> 48) + ',(int16_t)' + str(self.v3 & 0xFFFF) + ',(int16_t)' + str((self.v3 >> 16) & 0xFFFF) + ',(int16_t)' + str((self.v3 >> 32) & 0xFFFF) + ',(int16_t)' + str(self.v3 >> 48) + '}; ppx')
elif index == 4:
return self.valobj.CreateValueFromExpression('u32x8', 'uint32_t ppx[8] = {' + str(self.v0 & 0xFFFFFFFF) + ',' + str(self.v0 >> 32) + ',' + str(self.v1 & 0xFFFFFFFF) + ',' + str(self.v1 >> 32) + ',' + str(self.v2 & 0xFFFFFFFF) + ',' + str(self.v2 >> 32) + ',' + str(self.v3 & 0xFFFFFFFF) + ',' + str(self.v3 >> 32) + '}; ppx')
elif index == 5:
return self.valobj.CreateValueFromExpression('i32x8', 'int32_t ppx[8] = {(int32_t)' + str(self.v0 & 0xFFFFFFFF) + ',(int32_t)' + str(self.v0 >> 32) + ',(int32_t)' + str(self.v1 & 0xFFFFFFFF) + ',(int32_t)' + str(self.v1 >> 32) + ',(int32_t)' + str(self.v2 & 0xFFFFFFFF) + ',(int32_t)' + str(self.v2 >> 32) + ',(int32_t)' + str(self.v3 & 0xFFFFFFFF) + ',(int32_t)' + str(self.v3 >> 32) + '}; ppx')
elif index == 6:
return self.valobj.CreateValueFromExpression('u64x4', 'uint64_t ppx[4] = {' + str(self.v0) + ',' + str(self.v1) + ',' + str(self.v2) + ',' + str(self.v3) + '}; ppx')
elif index == 7:
return self.valobj.CreateValueFromExpression('i64x4', 'int64_t ppx[4] = {(int64_t)' + str(self.v0) + ',(int64_t)' + str(self.v1) + ',(int64_t)' + str(self.v2) + ',(int64_t)' + str(self.v3) + '}; ppx')
else:
return None
class Simd512Printer:
def __init__(self, valobj, internal_dict):
self.valobj = valobj
def update(self):
self.v0 = self.valobj.GetChildAtIndex(0).GetValueAsUnsigned()
self.v1 = self.valobj.GetChildAtIndex(1).GetValueAsUnsigned()
self.v2 = self.valobj.GetChildAtIndex(2).GetValueAsUnsigned()
self.v3 = self.valobj.GetChildAtIndex(3).GetValueAsUnsigned()
self.v4 = self.valobj.GetChildAtIndex(4).GetValueAsUnsigned()
self.v5 = self.valobj.GetChildAtIndex(5).GetValueAsUnsigned()
self.v6 = self.valobj.GetChildAtIndex(6).GetValueAsUnsigned()
self.v7 = self.valobj.GetChildAtIndex(7).GetValueAsUnsigned()
def num_children(self):
return 8
def get_child_index(self, name):
return int(name.lstrip('[').rstrip(']'))
def get_child_at_index(self, index):
if index == 0:
return self.valobj.CreateValueFromExpression('u8x64', 'uint16_t ppx[64] = {' + str(self.v0 & 0xFF) + ',' + str((self.v0 >> 8) & 0xFF) + ',' + str((self.v0 >> 16) & 0xFF) + ',' + str((self.v0 >> 24) & 0xFF) + ',' + str((self.v0 >> 32) & 0xFF) + ',' + str((self.v0 >> 40) & 0xFF) + ',' + str((self.v0 >> 48) & 0xFF) + ',' + str(self.v0 >> 56) + ',' + str(self.v1 & 0xFF) + ',' + str((self.v1 >> 8) & 0xFF) + ',' + str((self.v1 >> 16) & 0xFF) + ',' + str((self.v1 >> 24) & 0xFF) + ',' + str((self.v1 >> 32) & 0xFF) + ',' + str((self.v1 >> 40) & 0xFF) + ',' + str((self.v1 >> 48) & 0xFF) + ',' + str(self.v1 >> 56) + ',' + str(self.v2 & 0xFF) + ',' + str((self.v2 >> 8) & 0xFF) + ',' + str((self.v2 >> 16) & 0xFF) + ',' + str((self.v2 >> 24) & 0xFF) + ',' + str((self.v2 >> 32) & 0xFF) + ',' + str((self.v2 >> 40) & 0xFF) + ',' + str((self.v2 >> 48) & 0xFF) + ',' + str(self.v2 >> 56) + ',' + str(self.v3 & 0xFF) + ',' + str((self.v3 >> 8) & 0xFF) + ',' + str((self.v3 >> 16) & 0xFF) + ',' + str((self.v3 >> 24) & 0xFF) + ',' + str((self.v3 >> 32) & 0xFF) + ',' + str((self.v3 >> 40) & 0xFF) + ',' + str((self.v3 >> 48) & 0xFF) + ',' + str(self.v3 >> 56) + ',' + str(self.v4 & 0xFF) + ',' + str((self.v4 >> 8) & 0xFF) + ',' + str((self.v4 >> 16) & 0xFF) + ',' + str((self.v4 >> 24) & 0xFF) + ',' + str((self.v4 >> 32) & 0xFF) + ',' + str((self.v4 >> 40) & 0xFF) + ',' + str((self.v4 >> 48) & 0xFF) + ',' + str(self.v4 >> 56) + ',' + str(self.v5 & 0xFF) + ',' + str((self.v5 >> 8) & 0xFF) + ',' + str((self.v5 >> 16) & 0xFF) + ',' + str((self.v5 >> 24) & 0xFF) + ',' + str((self.v5 >> 32) & 0xFF) + ',' + str((self.v5 >> 40) & 0xFF) + ',' + str((self.v5 >> 48) & 0xFF) + ',' + str(self.v5 >> 56) + ',' + str(self.v6 & 0xFF) + ',' + str((self.v6 >> 8) & 0xFF) + ',' + str((self.v6 >> 16) & 0xFF) + ',' + str((self.v6 >> 24) & 0xFF) + ',' + str((self.v6 >> 32) & 0xFF) + ',' + str((self.v6 >> 40) & 0xFF) + ',' + str((self.v6 >> 48) & 0xFF) + ',' + str(self.v6 >> 56) + ',' + str(self.v7 & 0xFF) + ',' + str((self.v7 >> 8) & 0xFF) + ',' + str((self.v7 >> 16) & 0xFF) + ',' + str((self.v7 >> 24) & 0xFF) + ',' + str((self.v7 >> 32) & 0xFF) + ',' + str((self.v7 >> 40) & 0xFF) + ',' + str((self.v7 >> 48) & 0xFF) + ',' + str(self.v7 >> 56) + '}; ppx')
elif index == 1:
return self.valobj.CreateValueFromExpression('i8x64', 'int16_t ppx[64] = {(int8_t)' + str(self.v0 & 0xFF) + ',(int8_t)' + str((self.v0 >> 8) & 0xFF) + ',(int8_t)' + str((self.v0 >> 16) & 0xFF) + ',(int8_t)' + str((self.v0 >> 24) & 0xFF) + ',(int8_t)' + str((self.v0 >> 32) & 0xFF) + ',(int8_t)' + str((self.v0 >> 40) & 0xFF) + ',(int8_t)' + str((self.v0 >> 48) & 0xFF) + ',(int8_t)' + str(self.v0 >> 56) + ',(int8_t)' + str(self.v1 & 0xFF) + ',(int8_t)' + str((self.v1 >> 8) & 0xFF) + ',(int8_t)' + str((self.v1 >> 16) & 0xFF) + ',(int8_t)' + str((self.v1 >> 24) & 0xFF) + ',(int8_t)' + str((self.v1 >> 32) & 0xFF) + ',(int8_t)' + str((self.v1 >> 40) & 0xFF) + ',(int8_t)' + str((self.v1 >> 48) & 0xFF) + ',(int8_t)' + str(self.v1 >> 56) + ',(int8_t)' + str(self.v2 & 0xFF) + ',(int8_t)' + str((self.v2 >> 8) & 0xFF) + ',(int8_t)' + str((self.v2 >> 16) & 0xFF) + ',(int8_t)' + str((self.v2 >> 24) & 0xFF) + ',(int8_t)' + str((self.v2 >> 32) & 0xFF) + ',(int8_t)' + str((self.v2 >> 40) & 0xFF) + ',(int8_t)' + str((self.v2 >> 48) & 0xFF) + ',(int8_t)' + str(self.v2 >> 56) + ',(int8_t)' + str(self.v3 & 0xFF) + ',(int8_t)' + str((self.v3 >> 8) & 0xFF) + ',(int8_t)' + str((self.v3 >> 16) & 0xFF) + ',(int8_t)' + str((self.v3 >> 24) & 0xFF) + ',(int8_t)' + str((self.v3 >> 32) & 0xFF) + ',(int8_t)' + str((self.v3 >> 40) & 0xFF) + ',(int8_t)' + str((self.v3 >> 48) & 0xFF) + ',(int8_t)' + str(self.v3 >> 56) + ',(int8_t)' + str(self.v4 & 0xFF) + ',(int8_t)' + str((self.v4 >> 8) & 0xFF) + ',(int8_t)' + str((self.v4 >> 16) & 0xFF) + ',(int8_t)' + str((self.v4 >> 24) & 0xFF) + ',(int8_t)' + str((self.v4 >> 32) & 0xFF) + ',(int8_t)' + str((self.v4 >> 40) & 0xFF) + ',(int8_t)' + str((self.v4 >> 48) & 0xFF) + ',(int8_t)' + str(self.v4 >> 56) + ',(int8_t)' + str(self.v5 & 0xFF) + ',(int8_t)' + str((self.v5 >> 8) & 0xFF) + ',(int8_t)' + str((self.v5 >> 16) & 0xFF) + ',(int8_t)' + str((self.v5 >> 24) & 0xFF) + ',(int8_t)' + str((self.v5 >> 32) & 0xFF) + ',(int8_t)' + str((self.v5 >> 40) & 0xFF) + ',(int8_t)' + str((self.v5 >> 48) & 0xFF) + ',(int8_t)' + str(self.v5 >> 56) + ',(int8_t)' + str(self.v6 & 0xFF) + ',(int8_t)' + str((self.v6 >> 8) & 0xFF) + ',(int8_t)' + str((self.v6 >> 16) & 0xFF) + ',(int8_t)' + str((self.v6 >> 24) & 0xFF) + ',(int8_t)' + str((self.v6 >> 32) & 0xFF) + ',(int8_t)' + str((self.v6 >> 40) & 0xFF) + ',(int8_t)' + str((self.v6 >> 48) & 0xFF) + ',(int8_t)' + str(self.v6 >> 56) + ',(int8_t)' + str(self.v7 & 0xFF) + ',(int8_t)' + str((self.v7 >> 8) & 0xFF) + ',(int8_t)' + str((self.v7 >> 16) & 0xFF) + ',(int8_t)' + str((self.v7 >> 24) & 0xFF) + ',(int8_t)' + str((self.v7 >> 32) & 0xFF) + ',(int8_t)' + str((self.v7 >> 40) & 0xFF) + ',(int8_t)' + str((self.v7 >> 48) & 0xFF) + ',(int8_t)' + str(self.v7 >> 56) + '}; ppx')
elif index == 2:
return self.valobj.CreateValueFromExpression('u16x32', 'uint16_t ppx[32] = {' + str(self.v0 & 0xFFFF) + ',' + str((self.v0 >> 16) & 0xFFFF) + ',' + str((self.v0 >> 32) & 0xFFFF) + ',' + str(self.v0 >> 48) + ',' + str(self.v1 & 0xFFFF) + ',' + str((self.v1 >> 16) & 0xFFFF) + ',' + str((self.v1 >> 32) & 0xFFFF) + ',' + str(self.v1 >> 48) + ',' + str(self.v2 & 0xFFFF) + ',' + str((self.v2 >> 16) & 0xFFFF) + ',' + str((self.v2 >> 32) & 0xFFFF) + ',' + str(self.v2 >> 48) + ',' + str(self.v3 & 0xFFFF) + ',' + str((self.v3 >> 16) & 0xFFFF) + ',' + str((self.v3 >> 32) & 0xFFFF) + ',' + str(self.v3 >> 48) + ',' + str(self.v4 & 0xFFFF) + ',' + str((self.v4 >> 16) & 0xFFFF) + ',' + str((self.v4 >> 32) & 0xFFFF) + ',' + str(self.v4 >> 48) + ',' + str(self.v5 & 0xFFFF) + ',' + str((self.v5 >> 16) & 0xFFFF) + ',' + str((self.v5 >> 32) & 0xFFFF) + ',' + str(self.v5 >> 48) + ',' + str(self.v6 & 0xFFFF) + ',' + str((self.v6 >> 16) & 0xFFFF) + ',' + str((self.v6 >> 32) & 0xFFFF) + ',' + str(self.v6 >> 48) + ',' + str(self.v7 & 0xFFFF) + ',' + str((self.v7 >> 16) & 0xFFFF) + ',' + str((self.v7 >> 32) & 0xFFFF) + ',' + str(self.v7 >> 48) + '}; ppx')
elif index == 3:
return self.valobj.CreateValueFromExpression('i16x32', 'int16_t ppx[32] = {(int16_t)' + str(self.v0 & 0xFFFF) + ',(int16_t)' + str((self.v0 >> 16) & 0xFFFF) + ',(int16_t)' + str((self.v0 >> 32) & 0xFFFF) + ',(int16_t)' + str(self.v0 >> 48) + ',(int16_t)' + str(self.v1 & 0xFFFF) + ',(int16_t)' + str((self.v1 >> 16) & 0xFFFF) + ',(int16_t)' + str((self.v1 >> 32) & 0xFFFF) + ',(int16_t)' + str(self.v1 >> 48) + ',(int16_t)' + str(self.v2 & 0xFFFF) + ',(int16_t)' + str((self.v2 >> 16) & 0xFFFF) + ',(int16_t)' + str((self.v2 >> 32) & 0xFFFF) + ',(int16_t)' + str(self.v2 >> 48) + ',(int16_t)' + str(self.v3 & 0xFFFF) + ',(int16_t)' + str((self.v3 >> 16) & 0xFFFF) + ',(int16_t)' + str((self.v3 >> 32) & 0xFFFF) + ',(int16_t)' + str(self.v3 >> 48) + ',(int16_t)' + str(self.v4 & 0xFFFF) + ',(int16_t)' + str((self.v4 >> 16) & 0xFFFF) + ',(int16_t)' + str((self.v4 >> 32) & 0xFFFF) + ',(int16_t)' + str(self.v4 >> 48) + ',(int16_t)' + str(self.v5 & 0xFFFF) + ',(int16_t)' + str((self.v5 >> 16) & 0xFFFF) + ',(int16_t)' + str((self.v5 >> 32) & 0xFFFF) + ',(int16_t)' + str(self.v5 >> 48) + ',(int16_t)' + str(self.v6 & 0xFFFF) + ',(int16_t)' + str((self.v6 >> 16) & 0xFFFF) + ',(int16_t)' + str((self.v6 >> 32) & 0xFFFF) + ',(int16_t)' + str(self.v6 >> 48) + ',(int16_t)' + str(self.v7 & 0xFFFF) + ',(int16_t)' + str((self.v7 >> 16) & 0xFFFF) + ',(int16_t)' + str((self.v7 >> 32) & 0xFFFF) + ',(int16_t)' + str(self.v7 >> 48) + '}; ppx')
elif index == 4:
return self.valobj.CreateValueFromExpression('u32x16', 'uint32_t ppx[16] = {' + str(self.v0 & 0xFFFFFFFF) + ',' + str(self.v0 >> 32) + ',' + str(self.v1 & 0xFFFFFFFF) + ',' + str(self.v1 >> 32) + ',' + str(self.v2 & 0xFFFFFFFF) + ',' + str(self.v2 >> 32) + ',' + str(self.v3 & 0xFFFFFFFF) + ',' + str(self.v3 >> 32) + ',' + str(self.v4 & 0xFFFFFFFF) + ',' + str(self.v4 >> 32) + ',' + str(self.v5 & 0xFFFFFFFF) + ',' + str(self.v5 >> 32) + ',' + str(self.v6 & 0xFFFFFFFF) + ',' + str(self.v6 >> 32) + ',' + str(self.v7 & 0xFFFFFFFF) + ',' + str(self.v7 >> 32) + '}; ppx')
elif index == 5:
return self.valobj.CreateValueFromExpression('i32x16', 'int32_t ppx[16] = {(int32_t)' + str(self.v0 & 0xFFFFFFFF) + ',(int32_t)' + str(self.v0 >> 32) + ',(int32_t)' + str(self.v1 & 0xFFFFFFFF) + ',(int32_t)' + str(self.v1 >> 32) + ',(int32_t)' + str(self.v2 & 0xFFFFFFFF) + ',(int32_t)' + str(self.v2 >> 32) + ',(int32_t)' + str(self.v3 & 0xFFFFFFFF) + ',(int32_t)' + str(self.v3 >> 32) + ',(int32_t)' + str(self.v4 & 0xFFFFFFFF) + ',(int32_t)' + str(self.v4 >> 32) + ',(int32_t)' + str(self.v5 & 0xFFFFFFFF) + ',(int32_t)' + str(self.v5 >> 32) + ',(int32_t)' + str(self.v6 & 0xFFFFFFFF) + ',(int32_t)' + str(self.v6 >> 32) + ',(int32_t)' + str(self.v7 & 0xFFFFFFFF) + ',(int32_t)' + str(self.v7 >> 32) + '}; ppx')
elif index == 6:
return self.valobj.CreateValueFromExpression('u64x8', 'uint64_t ppx[8] = {' + str(self.v0) + ',' + str(self.v1) + ',' + str(self.v2) + ',' + str(self.v3) + ',' + str(self.v4) + ',' + str(self.v5) + ',' + str(self.v6) + ',' + str(self.v7) + '}; ppx')
elif index == 7:
return self.valobj.CreateValueFromExpression('i64x8', 'int64_t ppx[8] = {(int64_t)' + str(self.v0) + ',(int64_t)' + str(self.v1) + ',(int64_t)' + str(self.v2) + ',(int64_t)' + str(self.v3) + ',(int64_t)' + str(self.v4) + ',(int64_t)' + str(self.v5) + ',(int64_t)' + str(self.v6) + ',(int64_t)' + str(self.v7) + '}; ppx')
else:
return None
def __lldb_init_module(debugger, dict):
debugger.HandleCommand('type synthetic add -w simd -l simd.Simd128Printer __m128i')
debugger.HandleCommand('type synthetic add -w simd -l simd.Simd256Printer __m256i')
debugger.HandleCommand('type synthetic add -w simd -l simd.Simd512Printer __m512i')
debugger.HandleCommand('type category enable simd')
debugger.HandleCommand('type category disable VectorTypes')
Note that we are adding printers for three SIMD types here, grouped in the simd category, and then enabling that category. At the same time, we need to disable the VectorTypes category, otherwise the default vector printers (which print __m128i as two uint64 numbers, as seen before) would be used.
Setting things up Link to heading
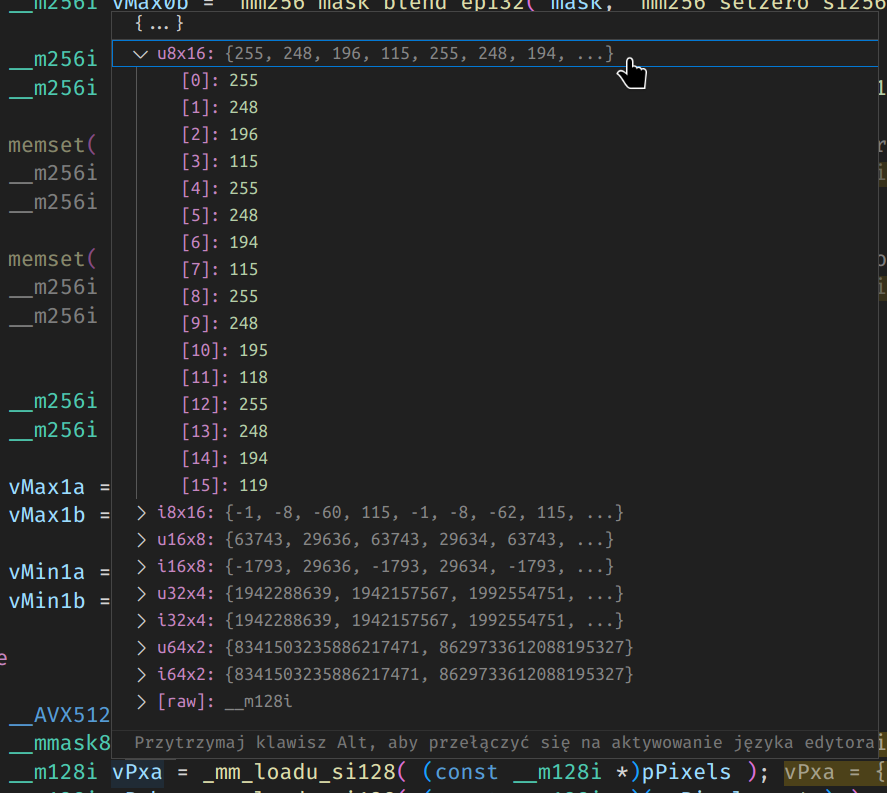
You will need to import the script in the debugger, for example by running command script import ~/simd.py in the debugger. Once this is done, the SSE/AVX registers will be printed in all possible lane configurations:
(lldb) v vPxa
(__m128i) vPxa = (8341503235886217471, 8629733612088195327)
(lldb) command script import ~/simd.py
(lldb) v vPxa
(__m128i) vPxa = {
u8x16 = {
[0] = 255
[1] = 248
[2] = 196
[3] = 115
[4] = 255
[5] = 248
[6] = 194
[7] = 115
[8] = 255
[9] = 248
[10] = 195
[11] = 118
[12] = 255
[13] = 248
[14] = 194
[15] = 119
}
i8x16 = {
[0] = -1
[1] = -8
[2] = -60
[3] = 115
[4] = -1
[5] = -8
[6] = -62
[7] = 115
[8] = -1
[9] = -8
[10] = -61
[11] = 118
[12] = -1
[13] = -8
[14] = -62
[15] = 119
}
u16x8 = ([0] = 63743, [1] = 29636, [2] = 63743, [3] = 29634, [4] = 63743, [5] = 30403, [6] = 63743, [7] = 30658)
i16x8 = ([0] = -1793, [1] = 29636, [2] = -1793, [3] = 29634, [4] = -1793, [5] = 30403, [6] = -1793, [7] = 30658)
u32x4 = ([0] = 1942288639, [1] = 1942157567, [2] = 1992554751, [3] = 2009266431)
i32x4 = ([0] = 1942288639, [1] = 1942157567, [2] = 1992554751, [3] = 2009266431)
u64x2 = ([0] = 8341503235886217471, [1] = 8629733612088195327)
i64x2 = ([0] = 8341503235886217471, [1] = 8629733612088195327)
}
You can run the script import command right in the middle of debugging, as shown above, or you can put it in the ~/.lldbinit file to run it each time you start the debugger.
If you are using the CodeLLDB extension in VS Code, you can add the following entry to the launch configuration in the launch.json file:
"initCommands": ["command script import ${workspaceRoot}/simd.py"]
This will integrate pretty printer in the debugger tooltips, as shown in the screenshot at the top.
[Citation needed]. ↩︎
Equivalent of a
2, 3, 0, 1SSE shuffle. ↩︎Contrary to some opinions, SIMD can be used for regular integer math. In fact, all the SIMD code I write does integer math only. Not a floating point in sight. So yes, there are
__m128,__m128d,__m128h, and so on, but I have zero interest in them. ↩︎For example,
__m128iis defined as along longwith some__attribute__magic to indicate it is 16-bytes wide:typedef long long __m128i __attribute__((__vector_size__(16), __aligned__(16)));. ↩︎